Мы уже рассказывали, как сделать так, чтобы пользователь зашел на сайт и не вернулся в выдачу, и делились своим чек-листом оптимизации поведенческих факторов, в который входит 35 пунктов проверки.
Теперь поговорим о другой стороне оптимизации — технической, которая отвечает за правильную индексацию, ранжирование страниц, быструю загрузку, корректное отображение блоков на разных устройствах. Косвенно это все тоже влияет на поведенческие — если сайт будет долго грузиться, пользователь уйдет, так и не оценив, какие полезные дополнительные блоки на странице мы разместили.
В рамках этой статьи подробно разберем один из пунктов технической оптимизации — проработку дублированных страниц. Дубли — это страницы с полностью или частично совпадающим контентом, одновременно доступные по разным адресам. Именно из-за них возникает конфликт интересов: нам нужно расширить индекс сайта за счет увеличения количества страниц, релевантных запросам пользователей, даже если на этих страницах схожий контент, а поисковой системе — избавиться от дублирующей информации.
На многих проектах, которые заходят к нам на аудит поискового продвижения, мы замечаем, что дубли либо игнорируются, либо подменяются на главную страницу или страницу категории с помощью 301 редиректа.
Это не самые лучшие решения. В первом случае можно нарваться на санкции поисковиков (АГС фильтр Яндекса, фильтр Панда от Гугла и т. д.) или потерять контроль над продвижением, если робот сам начнет определять, какие страницы индексировать, а какие — нет. Во втором случае сайту будет сложнее нарастить объем страниц в индексе и занять место в топе.
Ниже — несколько советов, основанных на нашем опыте, которые помогут вашему сайту и объем страниц нарастить, и санкции поисковиков обойти.
Создавайте для каждой характеристики товара страницы с новым URL и уникализируйте их
Мы продвигаем десятки интернет-магазинов и всем им рекомендуем создавать отдельные карточки для разных SKU одного и того же товара.
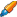
Если предлагаем куртку в трех цветах, то для каждого цвета делаем отдельную страницу с новым URL. Поисковик в этом случае считает, что у нас не 1 куртка, а 3.
Такой подход позволяет нам создавать видимость еще большего ассортимента в интернет-магазине. Когда пользователь ищет куртку, поисковая система постарается предложить ему сайт, где курток много, чтобы он с большей вероятностью нашел то, что ему надо. Если у нас SKU будут разнесены по разным страницам, а у наших конкурентов — нет, она поднимет наш сайт выше в выдаче, хотя ассортимент у нас с ними может быть одинаковым.
Но есть один минус — поисковые системы воспринимают такие страницы как частичные дубли. Мы-то с вами видим, что черная, белая и синяя куртки — это три разные вещи, а для роботов это 3 страницы с контентом, совпадающим на 99%. В итоге мы рискуем потерять в индексе несколько групп товаров.
На наших проектах мы эту задачу решаем так:
- Делаем микроразметку цвета. Этим убиваем сразу двух зайцев — показываем поисковым роботам, чем страницы различаются, и обогащаем сниппет в выдаче.
- Уникализируем Title и H1 для каждой карточки товара. «Комбинезон васильковый с темно-синими вставками» и «Комбинезон серый с черными вставками» — это для поисковых систем не одно и то же.
- Используем оригинальные изображения на каждой странице с проработкой атрибута Alt.
Чтобы не тратить время специалистов на рутинную работу, мы из всего массива товаров выбираем 5-10% тех, которые пользуются наибольшим спросом у пользователей, и оптимизируем вручную только их. Оптимизацию всех остальных карточек делегируем роботам, которые по шаблонам задают нужные нам параметры Alt, Title, H1 и т. д.
Указывайте, какая из страниц пагинации, сортировки, фильтрации главная
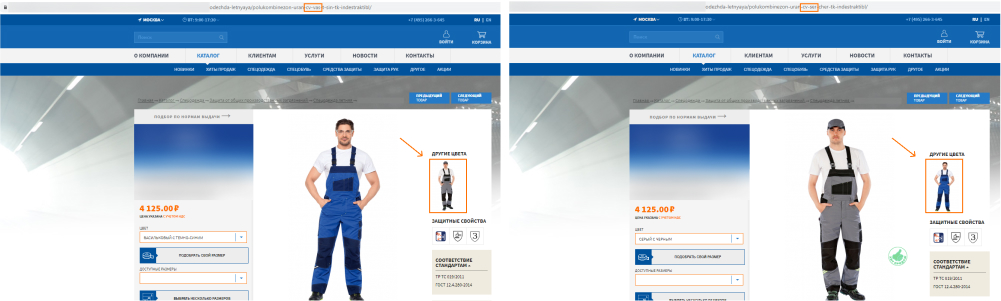
Сотни тысяч товаров на сайте — это хорошо. Еще лучше, когда пользователь в обилии ассортимента может легко ориентироваться. Для этого добавляем в каталог пагинацию (постраничную навигацию), возможность фильтрации и сортировки.
Теперь товары выводятся на странице по несколько штук (в нашем примере — по 20), их можно отфильтровать по цвету, техническим характеристикам или бренду, отсортировать по возрастанию цены или рейтингу.
Только вот робот не понимает, что страница, на которую мы выводим 20 первых товаров, и страница, на которую мы выводим 20 следующих — разные. Для него это дубли — он видит одинаковые пункты меню, боковые блоки, описание категории и т. д. Точно так же он не понимает, что страница, где товары отсортированы по убыванию цены — это для пользователя не то же самое, что страница, где товары отсортированы по возрастанию цены.
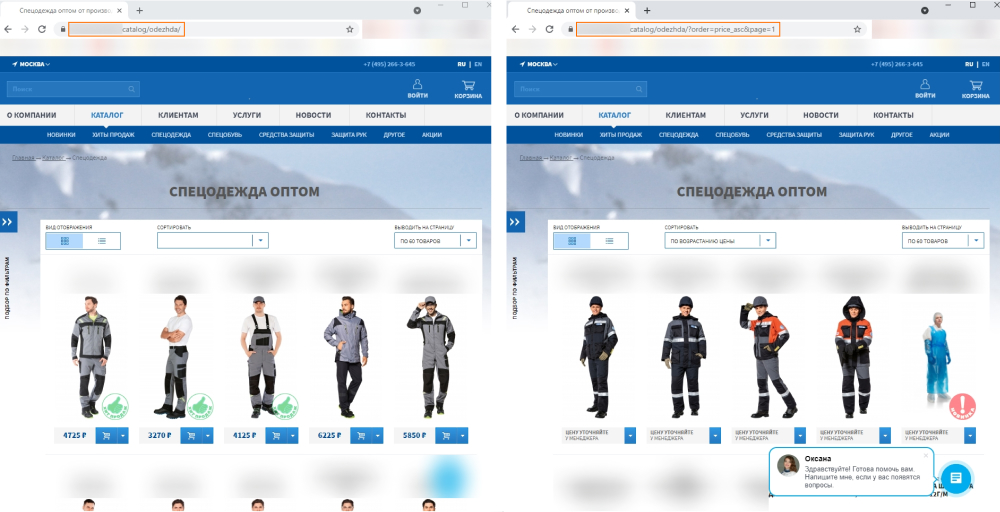
Если робот видит несколько дублированных страниц, он может сам выбрать основную (каноническую) и сканировать ее чаще, чем дубли. Но не факт, что его выбор будет совпадать с нашим. В результате трафик и ссылочный вес будут не сконцентрированы на одной странице, а размыты между несколькими. Нам в такой ситуации важно подсказать поисковику, какая страница у нас в приоритете для продвижения — если речь о пагинации, то самая первая, если о фильтрации или сортировке — то исходная.
Для этого на все дубли мы проставляем атрибут rel="canonical" с адресом основной страницы.
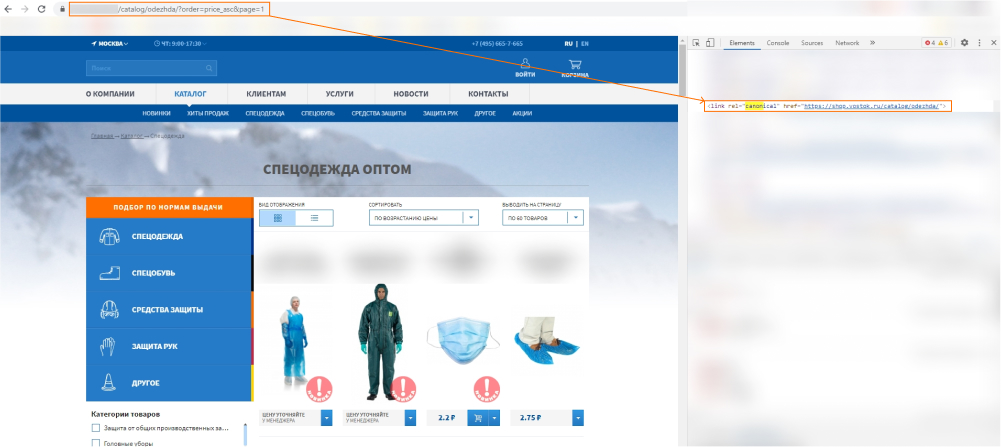
Для поисковика это знак, что страницы между собой связаны — он не будет тратить краулинговый бюджет на сканирование 2–3 аналогичных страниц, а сосредоточится на одной. Стоит отметить, что Гугл и Яндекс позиционируют rel="canonical" как рекомендацию. То есть, проставляя атрибут, мы подсказываем поисковикам, какая из страниц исходная, но 100% гарантии, что они возьмут именно ее в продвижение, нет.
Определяйте, какая из страниц одного и того же товара с разными адресами приносит больше трафика, и делайте ее основной
Такие дубли могут появиться из-за настроек CMS, непродуманной структуры сайта или того, что товар относится к разным категориям.
Часто бывает так, что на одну и ту же страницу товара можно выйти разными способами: перейти сразу из каталога («Каталог → Inf Oreo») или воспользоваться рубрикатором («Интерьер → Трековые системы → INFINITY SMART TRACK → Светильники → Inf Oreo»).
Поисковые системы воспринимают это не как различные пути к одной и той же странице, а как дубли.
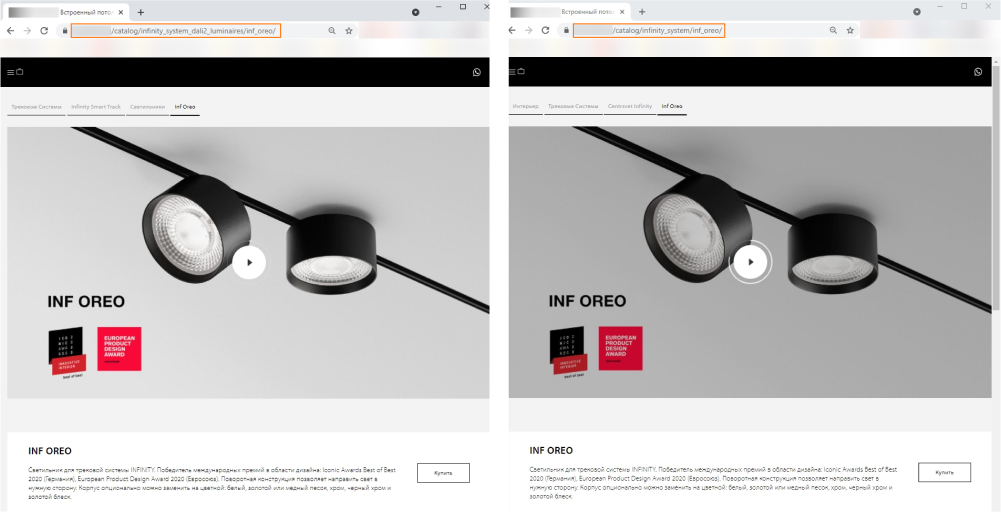
Так же, как и в предыдущем случае, эти страницы нужно склеить и выбрать из них ту, которую мы хотим продвигать. В отличие от дублей, появившихся в результате пагинации или сортировки, здесь не так очевидно, какая страница должна быть в приоритете. Поэтому нам надо сначала определить, на какую из них идет больший трафик — она и будет для нас основной. На остальные дубли мы будем проставлять атрибут rel="canonical" с ее адресом.
Для нашего проекта мы посмотрели в Гугл Аналитике, что больше всего трафика поступает со страницы, которую пользователи находят не через каталог всех товаров, а через раздел «Интерьер».
В отличие от настройки 301 редиректа, такой способ позволяет сохранить число страниц в индексе, так как все дубли с разными адресами останутся доступны пользователям, и при этом не навредить репутации сайта большим количеством неуникального контента.
И это еще не все
Дубли — это лишь один из 41 пункта, по которым мы в агентстве проводим техническую оптимизацию сайтов. Остальные будем постепенно разбирать в следующих статьях, поэтому подписывайтесь на нашу рассылку, чтобы их не пропустить. А чтобы вы могли уже сейчас начать устранять препятствия, которые мешают вашему сайту выйти в топ, предлагаем вам в помощь наш чек-лист.