В маркетинге мы предпочитаем опираться на математику, а не на интуицию. Если есть задача проверить семантику на полноту — значит, должен быть инструмент, который перетрясет собранные фразы и покажет, где и что еще можно добрать. Сервисов аналогичных нет, поэтому мы нашу внутреннюю модель вынесли в Excel-файл — скачивайте и пользуйтесь.
Что вам понадобится: фразы и их частоты — общие и точные.
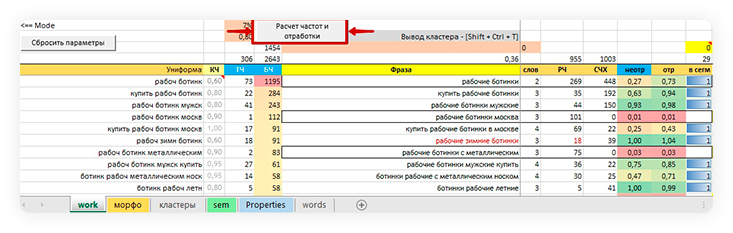
Принцип такой: вносим в Excel-файл фразы и частоты, жмем на кнопку и через несколько секунд, когда сформируются связи «фраза-хвост» и отсекутся доли нерелевантного объема, по маркерам определяем, где мы не доработали.
А теперь подробнее.
Идеально отработанная семантика
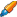
Если семантика отработана идеально, Excel-файл выглядит так:
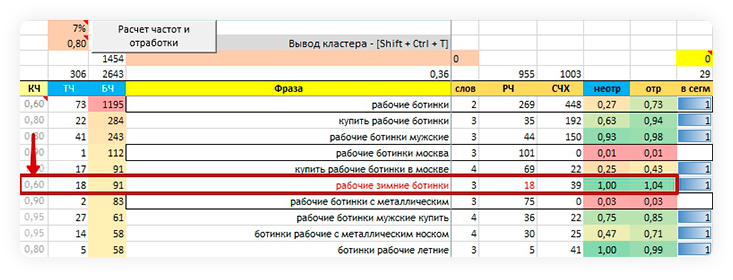
- значения в столбце H (расчетная частота) близки к значениям в столбце D (точная частота) у всех фраз, кроме низкочастотных и тех, в которых больше всего значимых слов;
- столбец J (коэффициент отработки) зеленого цвета;
- столбец K (коэффициент неотработки) зеленого цвета.
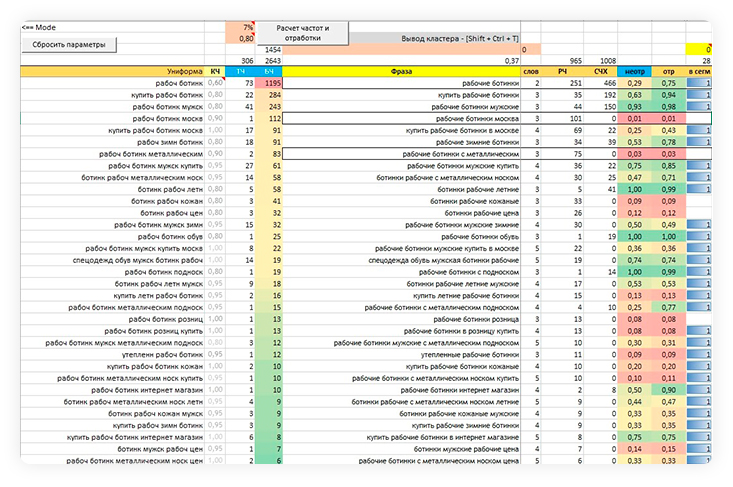 Такой результат достигается через 1-2 итерации
Такой результат достигается через 1-2 итерации
Неполная семантика: что упустили и как доработать
По маркерам файла мы можем понять 3 момента.
- Мы не добрали хвосты.
- Не досчитали трафика.
- Собрали некачественные хвосты.
Не добрали хвосты
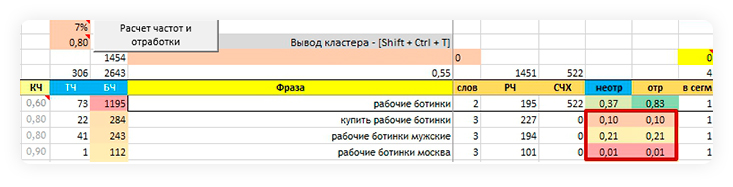
Если для какой-то фразы (скажем, «Защитная каска») мы упустили хвост со средней или высокой частотой («Защитная каска с наушниками»), мы увидим это по маркерам в файле.
Хвост — дочерняя фраза («Защитная каска с наушниками»), которая состоит из материнской фразы («Защитная каска») и хотя бы одного дополнительного слова («Наушник»)
Маркеры:
В столбце J (Коэффициент неотработки) и/ или в столбце K (Коэффициент отработки) ячейки не зеленого цвета, а желтого, оранжевого или красного (чем больше упустили хвостов, тем краснее цвет).
Что делать:
Идем в вордстат — вбиваем каждую такую фразу с минус-словами, находим для нее не включенные релевантные частотные хвосты и добавляем их в семантику.
Если таких хвостов нет, значит, дело не в том, что мы чего-то недобрали, а в том, что мы неправильно определили, какой релевантный объем трафика принесет фраза. Мы включили в него и мусорный объем. Для точного прогноза мусорный объем нужно отсечь — уменьшить коэффициент чистоты в столбце С.
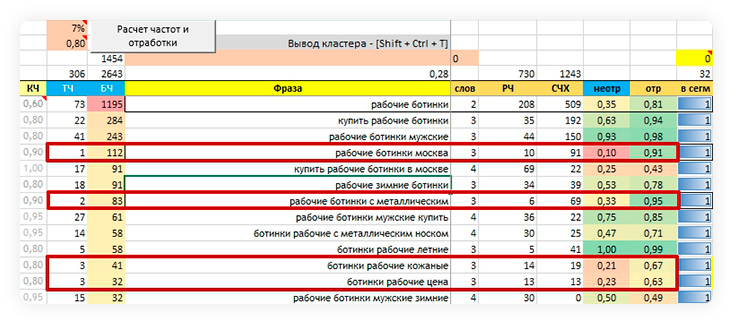
Собрали некачественные хвосты
Если мы включили в семантику хвост с низкой точной частотой, файл нам это тоже покажет.
Маркер:
Значение в столбце J (Коэффициент неотработки) меньше, чем значение в столбце K (Коэффициент отработки).
Что делать:
В столбце P ставим значение 0 — тогда эта фраза не будет учитываться и мы не возьмем ее в продвижение. Так мы сэкономим деньги, потому что у нее была бы высокая цена за пользователя
Не досчитали трафика
Иногда мы можем для какого-то запроса не точно спрогнозировать трафик — посчитать, что фраза приведет 15 человек, а, на самом деле, она может привести 20. Такие случаи файл нам тоже показывает, чтобы мы не удалили фразу, которую по ошибке посчитали бы мало полезной.
Маркеры:
Текст в столбце F красного цвета.
Что делать:
Увеличиваем коэффициент чистоты в столбце С.
Подготовка файла к работе
Скачайте шаблон и выполните следующие подготовительные шаги.
1. Внесите фразы
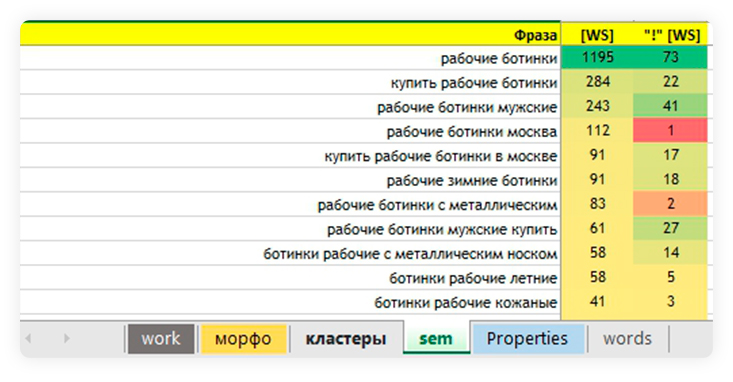
Откройте лист sem. Внесите в столбец А собранные фразы, в столбец B — их общие частоты, а в столбец С — точные частоты. Скопируйте эти же фразы (или сформируйте из них любую другую выборку) в столбец F листа work.
2. Задайте правила для создания униформ
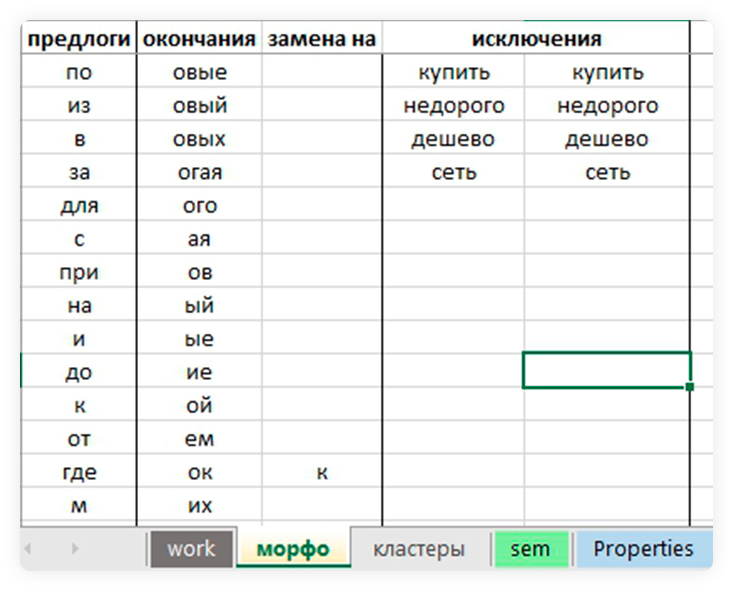
Перейдите на лист «Морфо». Здесь собраны предлоги и окончания, которые будут игнорироваться, потому что они не считываются поисковиками как смысловые. Вы можете задавать на этом листе свои правила и исключения.
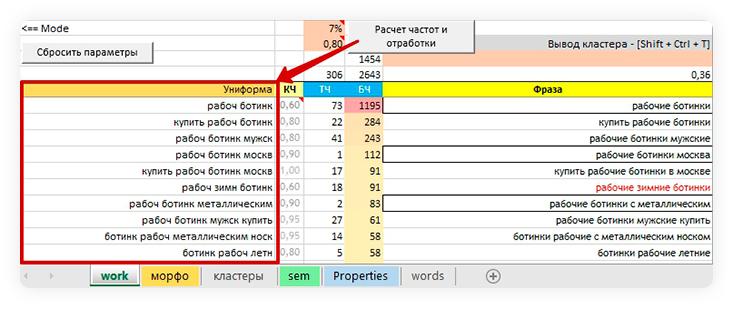
После того как на четвертом шаге вы нажмете на кнопку «Расчет частот и отработки», по этим правилам для каждой фразы в столбце B сгенерируются униформы, которые однозначно характеризуют фразы.
3. Установите коэффициент чистоты
Мы делаем это для того, чтобы учитывать только релевантные запросы по каждой фразе. Например, фразу «Средства индивидуальной защиты» могут вбивать в поисковиках 20000 раз за месяц. Но 30% из этих запросов — информационка. И нам нужно это учитывать, чтобы мы не считали, что у нас трафика с этой фразы будет больше.
Перейдите на лист «Properties».

Опираясь на свой опыт, знание проекта и отрасли, задайте базовый коэффициент чистоты.
Например, если вы считаете, что фразы из одного слова («Каски», «Спецодежда») содержат, в среднем, 45% мусора, поставьте в столбце D коэффициент чистоты — 0,55.
Ниже идут уровни вложенности: +1 слово (фразы из двух слов), + 2 слова (фразы из трех слов), + 3 слова (фразы из четырех слов). Для них также проставьте коэффициенты чистоты в столбце D. На скрине это: 0,65, 0,85 и 0,95. Обычно, чем длиннее фраза, тем меньше она замусорена.
Потом для отдельных фраз можно будет увеличить или уменьшить коэффициент чистоты. Это вы увидите по маркерам (мы их описали выше). Коэффициент чистоты для отдельной фразы можно поменять на листе «Work», в столбце С.
4. Нажмите на кнопку «Расчет частот и отработки»
Через несколько секунд уже можно анализировать маркеры и дорабатывать семантику.
Экономия
Кажется, сложно, но на деле это займет 10-20 минут. Проделанная работа позволит корректно сформировать продвигаемый сегмент, привести максимальный трафик и не переплачивать за пользователей.
Так что скачивайте файл, разбирайтесь, пользуйтесь или обращайтесь за продвижением к нам.