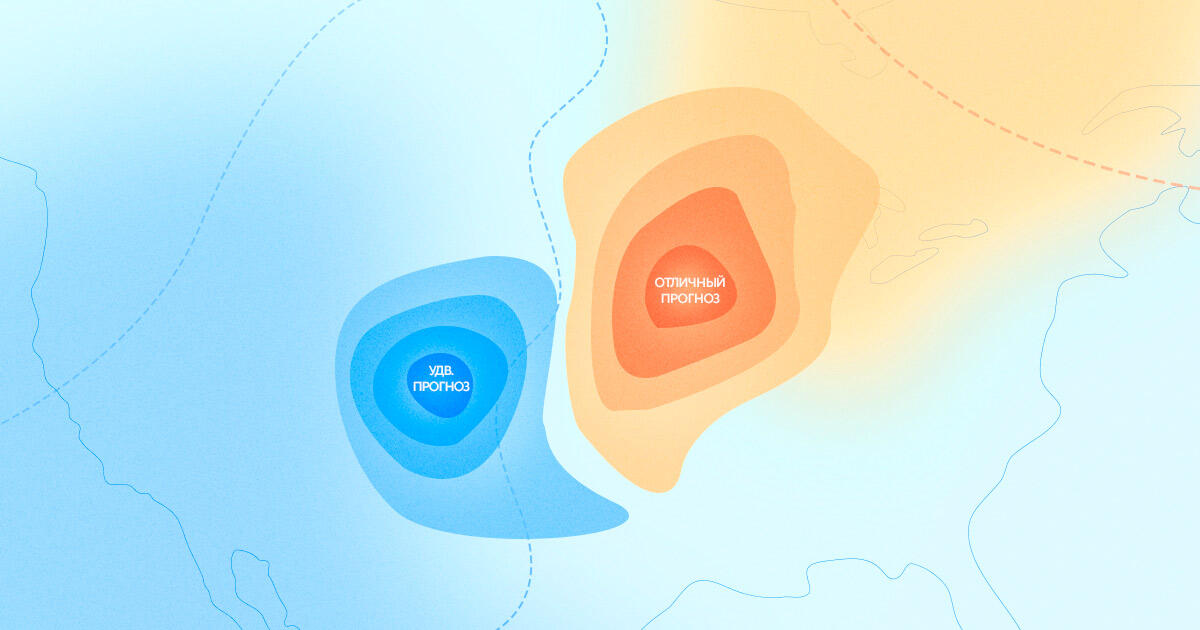

Методика предназначена для экспресс-прогнозирования трафика сайта — перспектив проекта в целом и прироста по нескольким новым направлениям развития в рамках конкретного рыночного сегмента по двум описанным сценариям. Используется, в основном, на этапе пресейла. Пригодится SEO-специалистам, стратегам, аналитикам и маркетологам.
Рассмотрим базовые положения нашей модели, а затем пробежимся по ключевым этапам технологии, затронув наиболее важные моменты.
Поддержка принятия решения
Мы используем простую систему поддержки принятия решения и ее достаточно для прогноза. На выходе получаем численное описание и визуализацию по трем сценариям: без продвижения, стандартный и оптимистичный.
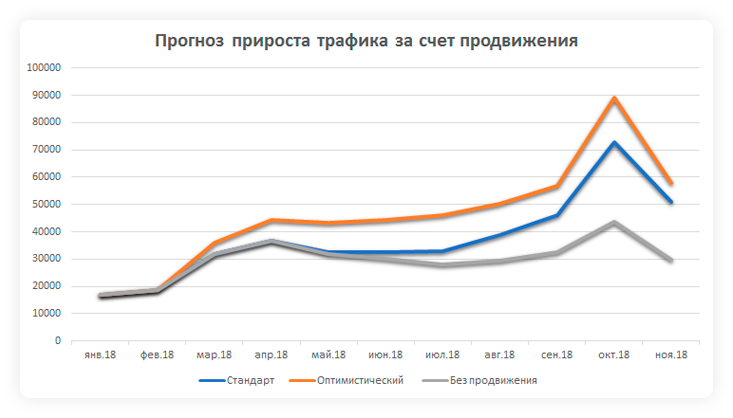
Прогнозируем на год вперед
Для формирования сценариев продвижения, выбора кривой тренда и оценки чистоты фразы проводим экспресс-анализ проекта, смотрим конкурентов и выдачу по запросам, вычищаем объем спроса, подбираем коэффициенты.
Входные данные
На этом этапе достаточно данных Гугл Аналитикс и общих частот опорных фраз. Например, «купить шины» и «купить колеса». Обычно подбираем одну фразу на одну категорию и рекомендуем использовать от трех до семи опорных фраз.
Для прогноза суммарного органического трафика нужны сеансы минимум за год, иначе скользящая и запаздывающая функция в случае значительной сезонности пропустит начало пика или спада — значение будет скорректировано только на следующий месяц. Если таких данных нет, то рекомендуем использовать один из трех вариантов выбора базовой кривой:
постоянное среднее за имеющийся период;
среднее за период с коэффициентом тренда (опасно при большой сезонности и малом количестве информации);
ноль трафика, считать только прирост за счет продвижения.

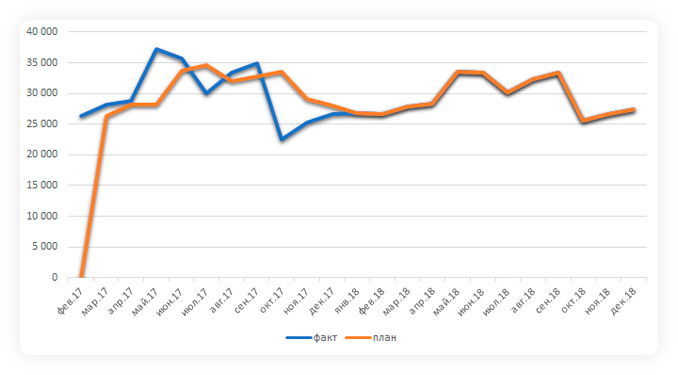
Прогнозная функция пропустила начало пика в мае и спад в октябре. Только на второй год кривая стала повторять сезонные колебания
Как мы составляем точный прогноз
Заполняем область ретроспективы спроса на первом листе. Импортируем из Кей Коллектора данные сезонности опорных фраз и размещаем их в зону ниже второго розового разделителя.
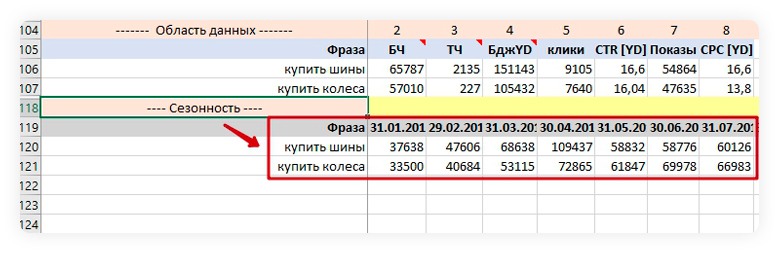
Область для выгрузки данных сезонности
Получаем коэффициент тренда и прогноз по общему нечищенному спросу со всех опорных фраз. Коэффициент тренда показывает общую тенденцию: как за последние 12 месяцев изменился спрос по сравнению с позапрошлым годом.

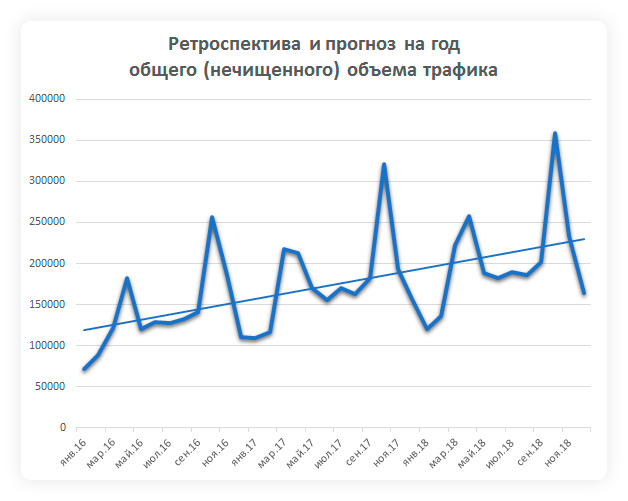
Прогноз общего объема запросов по имеющимся опорным фразам
Коэффициент тренда — 1,3
Подбираем коэффициент сигмоидальных функций через надстройку «Поиск решения» в Экселе или плагином в Гугл-спредшите с аналогичными возможностями.
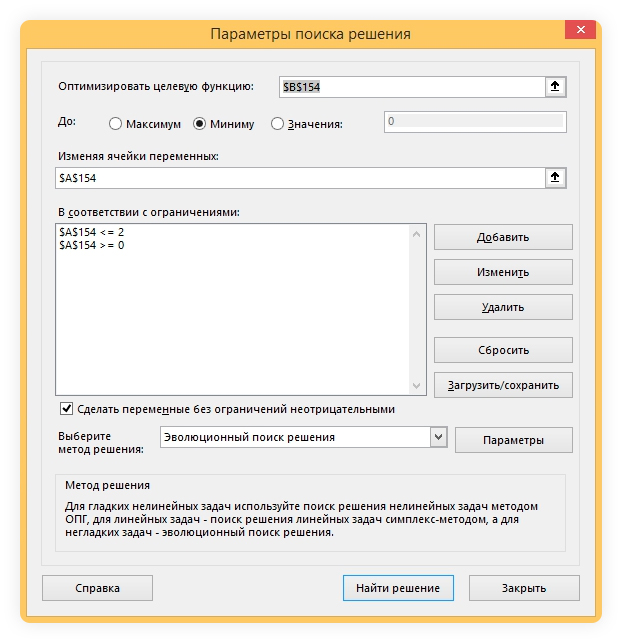
Настройки для поиска оптимальной сигмоиды по данным за два года
Задача — найти две сигмоиды, наиболее близко расположенные к фактическим данным. Сравнение производим на отрезках в один и два года.
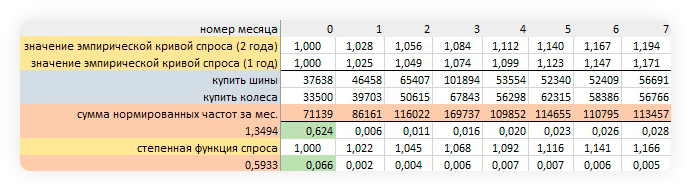
Векторы из значений функций тренда на прогнозный период: две подобранные сигмоиды и степенная функция
Выбираем одну из сигмоид или используем степенную функцию на основе прогноза спроса, перспектив проекта и активности конкурентов по данному сегменту рынка. Рекомендуем выбирать одну из сигмоид при прогнозе на насыщение спроса и высокую конкурентность, степенную функцию — при прогнозе на бурный рост спроса и слабую активность конкурентов.
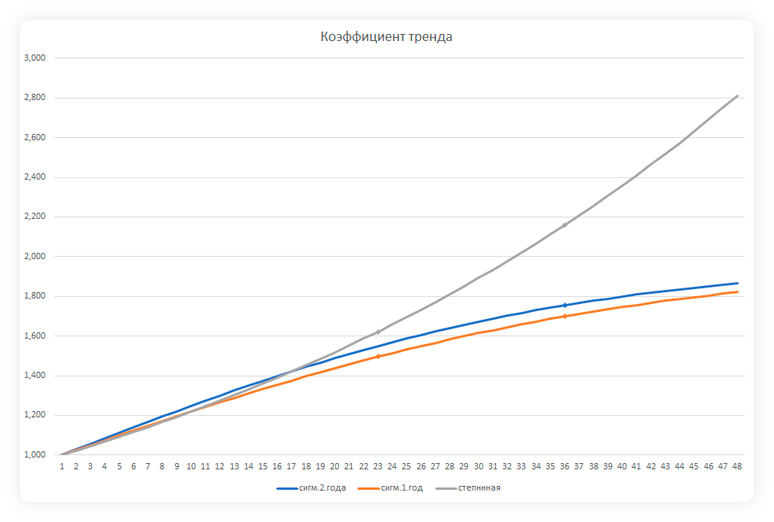
Графическое представление функций тренда для принятия решения аналитиком. Годовой коэффициент тренда в данном случае — 1,30
Нормируем фактические данные на коэффициент тренда в точке, равной одному месяцу. Получаем функцию сезонности. Используем понижающий коэффициент влияния, равный 0,8 — считаем, что для сезонности значения первого года менее значимы, чем второго.

Сезонные коэффициенты опорных фраз (1) и общий коэффициент сезонности (2)
Проводим технический анализ по методике:
Выбираем функции и вектор весовых коэффициентов, их влияния в прогнозных точках — месяцах.
Произведение вектора значений выбранных функций и вектора весов, разделенное на сумму весов — есть прогнозное значение для конкретного месяца.
Протягиваем. Прогноз по сценарию «без продвижения» составлен.
Область расчета прогнозного значения трафика по выбранным функциям и их весам
1 — функции и вектор весовых коэффициентов
2 — сумма весов
3 — прогнозное значение
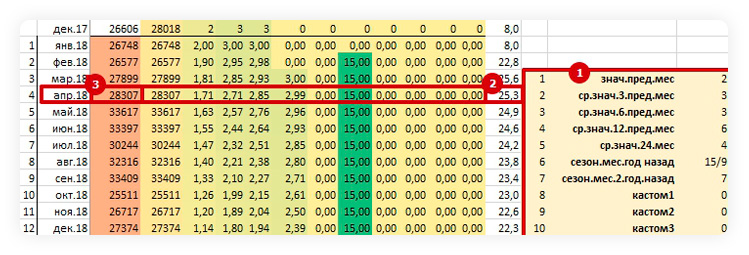
Заполняем блок расчетных частот опорных фраз:
Из общей частоты для выбранного региона вычищаем объем минус-словами, формирующими наибольшее количество мусора, сохраняем их в ячейку под фразой и указываем частоту с учетом минус-слов.
Указываем «коэффициент чистоты» для текущего, уже заминусованного кластера — примерную долю объема полезных запросов.
В результате получаем расчетную частоту и итоговый коэффициент чистоты полезного объема, которые будут использоваться в прогнозе.
Повторяем пункты
1-4 для всех фраз и интересующих нас регионов.
Заполнение блока расчетных частот кластеров

Составляем прогноз трафика проекта для стандартного и оптимистического сценариев продвижения.
Заполнение сценариев — финальная и самая ответственная часть работы специалиста. Количество сеансов с органики вычисляется с учетом двух коэффициентов — среднего CTR позиции и коэффициента вариации, указывающему долю достигших позиции фраз.
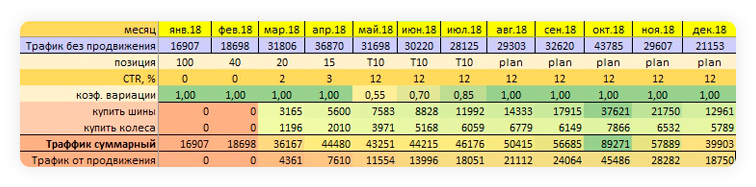
Пример заполнения оптимистичного сценария продвижения
Так получаем таблицу итогового трафика и прироста по месяцам, а также графическое представление, пример на первом изображении в статье.
Что улучшит точность прогноза и автоматизацию
1. Подход к прогнозу через расчетные частоты и стабильный трафик на проекте. По уже собранной семантике для устойчивых проектов, находящихся долгое время на продвижении, задача прогнозирования решается достаточно точно.
2. Автоматизация и точность базового SEO-анализа проекта, конкурентов, сегментов рынка и ниши в целом. В том числе определением того, кто из выдачи не является конкурентом и за какие позиции мы можем бороться.
3. Регрессионный анализ или использование нейросетей при расчете тренда и скользящей функции прогноза.