Мы ведем блог для директоров по performance-маркетингу, клиентские контент-проекты и судим о качестве контента по двум признакам:
- Целевая аудитория считает его ценным (плюс к лояльности).
- Он влияет на ее покупательское поведение (плюс к лидогенерации).
Понять, насколько контент соответствует второму признаку, просто. Для этого нужно в системах аналитики настроить цели: «переход на страницу услуги», «заявка», «покупка», «добавление товара в корзину», «добавление товара в избранное», «клик по номеру телефона».
Все становится сложнее, когда проверяешь контент на соответствие первому признаку. Даже когда в блоге есть возможность оценивать и комментировать статьи, неправильно судить о качестве контента только по микроконверсиям — в этом случае, мы не учитываем тех, кто их не совершил. Остается неизвестным, сколько человек не поставили лайк, но при этом поставили у себя в голове галочку: «Хороший материал!».
Чтобы разобраться, насколько ценный мы выпускаем контент, раньше мы просто отслеживали метрики вовлеченности.
Метрики вовлеченности в блоге:
- Средняя длительность сеанса;
- Количество просмотренных страниц/сеанс;
- Коэффициенты микроконверсий:
- отправка комментариев;
- клики по схемам/интерактивным элементам;
- отметки «Нравится»;
- перепосты в соцсети;
- отправка форм обратной связи;
- Конверсии в подписки на сайте;
- Средняя дочитываемость статей;
- Активное время на странице.
Метрики вовлеченности в каналах посева:
- CTR платных промо статей;
- Click rate email-рассылок с посевом;
- На сторонних площадках и в соцсетях:
- комментарии;
- отметки «Нравится»;
- шеры.
Они давали хороший контекст для размышлений. Почему одни статьи дочитывают, а другие нет? Почему эта статья набрала больше микроконверсий, чем эта? Почему на эти статьи кликали реже, чем на эти?
Но всегда оставались неудобные вопросы, вроде: «Хорошо, вот две статьи. Одну редко дочитывают, но зато активно переходят с нее на другие статьи и остаются в блоге. Другую дочитывают чаще, но после этого почти никогда не открывают что-то еще, уходят с сайта и не возвращаются. Какая статья лучше?».
В попытках ответить на эти вопросы мы пришли к тому, чтобы присвоить вес каждой метрике и вывести единую формулу вовлеченности в контент.
Пример формулы
Сейчас мы пробуем для каждого проекта выводить свою формулу. Определяем с клиентом задачу, расставляем приоритеты, отбираем метрики, которые можем отслеживать, и присваиваем каждой метрике вес.
Вот пример формулы для проекта в сфере образования, на котором приоритетная задача — оценить качество контента, предлагаемого аудитории, с точки зрения ее погружения в каждый конкретный материал.
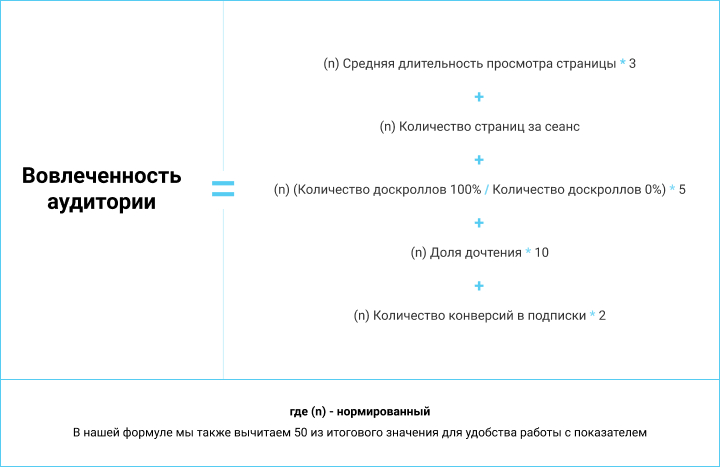
Задаем ее в спредшите:
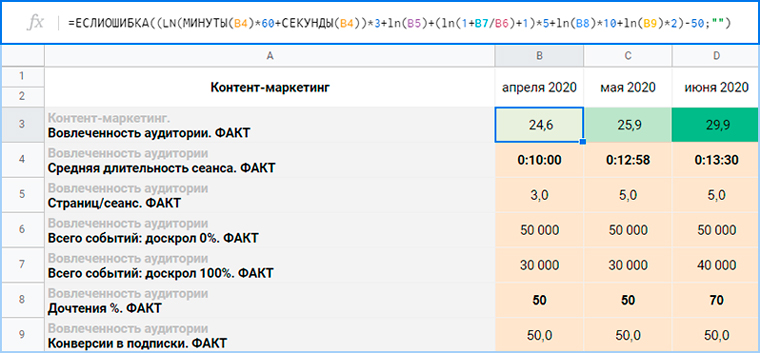
Формула учитывает влияние одних метрик на другие.
Например, в мае, по сравнению с апрелем, на сайте увеличилась средняя длительность сеанса, но при этом соразмерно увеличилось и количество просматриваемых статей, а дочтения остались на прежнем уровне. Коэффициент вовлеченности стал выше, но не значительно.
А в июне вместе со средней длительностью сеанса выросли дочтения. Коэффициент подскочил вверх. Это потому что на проекте приоритеты расставлены так, что вес у количества просмотренных страниц за сеанс меньше, чем у дочтений.
То есть нам важно, чтобы росли все показатели вовлеченности, в том числе и количество просмотренных страниц, поэтому мы от него не отказываемся, но нам важно и за счет чего это происходит: за счет того, что статьям стали больше уделять времени, или за счет того, что стали их бросать на середине и перескакивать с одной на другую. Формула нам помогает удерживать фокус на приоритетных метриках — когда вовлеченность растет благодаря им, коэффициент становится значительно выше, когда не благодаря им — не значительно. А когда приоритетные для нас метрики падают, а растут второстепенные, общий коэффициент вовлеченности становится ниже.
Если у вас похожие цели, можете ориентироваться на нашу формулу. Если нет — вывести свою.
Что учесть, когда будете выводить свою формулу вовлеченности в контент
- Определите показатели, которые хотите отслеживать и можете настроить.
Google Analytics не отслеживает, например, процент доскроллов статей. А нам для формулы нужен был этот показатель. Настраивали отдельно.
- Нормируйте показатели.
Показатели, измеряемые в разных шкалах (время, проценты, числа), переведите в одну (числа).
Показатели, имеющие разную размерность (единицы, тысячи) приведите к сопоставимому виду через один из методов нормирования (балльное шкалирование, центрирование, линейное масштабирование или логарифмирование). Это необходимо, чтобы размерность отдельных показателей не оказывала влияния на результат сложения с другими, возможно, более значимыми, показателями.
У нас нормирование зашито в формулу расчета.
- Задайте формулу расчета итогового показателя вовлеченности в удобном для вас сервисе.
На одних проектах мы делаем это в спредшите, где соотносим план-факт по месяцам. На других — настраиваем виджет с формулой расчета в отчете Google Data Studio. Как удобно клиенту.
Мы не утверждаем, что этот вариант — идеальный, но пока мы пришли к такому решению и нас радует возможность дать клиентам простой ответ на простой вопрос: «Ценит ли целевая аудитория контент, который мы выпускаем?». Четко — да/нет. Без переключения с отчета на отчет в Google Аналитике, долгих рассуждений и интерпретаций. Формула этот ответ дает. И они ему доверяют, потому что понимают, из чего он складывается, так как сами ставят задачу и приоритезируют показатели при разработке формулы.